SteemSQL - Database updated and ready for Communities

The long-awaited Communities have been launched today. That’s really great news as it is in line with what has been announced by Steemit inc.
The trick with communities is that it doesn’t require any change in the Steem blockchain protocol (i.e. it doesn’t require a hard fork) and deploy its new features by leveraging existing technology.
I will not go into too detailed explanations, but technically and basically, a community is a Steem account whose name looks like hive-NNNNNN where NNNNNN is the community identifier. Communities will then be managed with this account by broadcasting custom_json operations.
To publish in a community, you just need to use this identifier as the main tag of your post. It's that simple. Smart isn't it?
Why a change in SteemSQL database?
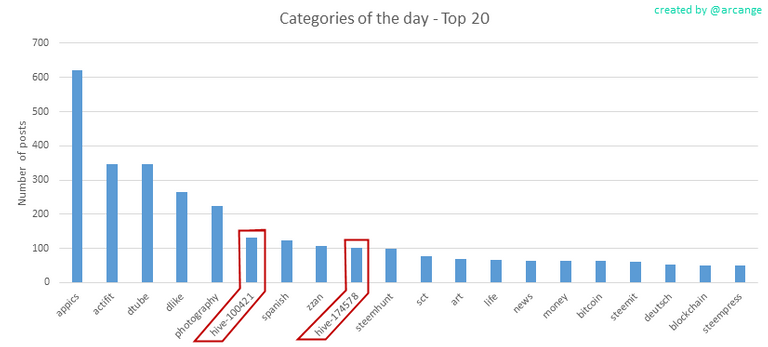
In this picture taken from my Steem statistics, we can see which tags are the most used. But, as you can see, there is now two intruders in the group: hive-100421, which is the Threespeak community, and hive-174578, which is the OCD community. And guess what, I bet we will soon see only "hive-" tags in this chart.
This means the category column of the Comments table in SteemSQL, which stores the main tag of each post, will now roughly contains only hive-nnnnnn values.
Not only is it less user-friendly (think of the previous categories like pictures, cats, stats, steem, …), but less efficient to search for posts matching a specific tag.
The main reason is that the tags will now all move into the json_metadata column, and this column has no index on it. On top of it, it contains an “unvalidated’ JSON data structure that you need to parse to retrieve information, either using complex and resource-consuming SQL queries or client-side processing.
Enter the new Tags table
A new Tags table has been created that will store all the tags of all the posts published on the steem blockchain since its inception.
It contains only 2 columns: comment_id and tag
comment_id is a foreign key containing the ID of the post in the Comments table.
tag is, of course, one of the tags used to publish the post.
To retrieve all posts related to a specific tag, for example.cats, you will issue the following SQL query:
SELECT
Comments.author,
Comments.permlink
FROM
Tags
INNER JOIN Comments ON Tags.comment_id = Comments.ID
WHERE
Tags.tag = 'cats'
High performances
SteemSQL has been designed to provide very high performances. But what about when it comes to extracting all the tags from the millions of posts that have been published for almost four years? For the number lover, here are some.
The Steem blockchain contains, as of writing 84,090,247 posts and comments. Although technically comments may contain tags, we are not interested in these.
That still leaves us 18,106,842 posts and the number of tags it can contain is limited only by the front-end that was used to publish them and by the amount of data that a block can contain.
When spitting apart all the tags from those posts, one found itself with an impressive amount of 76,771,968 tags that may grow exponentially now that communities are out.
Therefore, I had to implement advanced column-based data storage and query processing to provide SteemSQL with the ability to run performant real-time analytics on a transactional workload.
The results are impressive. The above queries yield a list of 32362 posts about cats, filtered out of the 77M tags, in less than 6 seconds. I know some who will enjoy this!
Limits
To achieve such performances, and reduce storage resource consumption, I had to filter some garbage. Therefore, empty tags (yes, there were some) and tags with more than 32 characters have been ignored.
You may wonder why one would use a tag with more than 32 characters as it is impractical and quite unreadable. But FYI, I found thousands of them, the biggest ones being pure garbage strings of 4000 characters. Shitty spammers.
SteemSQL now has its own community!
You are never as well served as by yourself. So I created a SteemSQL community where you can publish any post related to SteemSQL. I hope to see many of you and, who knows, maybe one day the tag hive-146513 will appear in my statistics.
Hmmm, that makes me think that I should update these ones to display some more user-friendly text. Damn... let's go back to work 😅
Support
If you have any questions or need assistance with SteemSQL, support is provided on the dedicated SteemSQL channel on steem.chat,
You can also contact me directly on steem.chat, Discord or Telegram
Enjoy this new feature and thanks for reading!
Hey man ... great job ... will test it out soon :)
Thank you @dalz. Feedback is welcome ;)
I appreciate your great work in service of the Steem community. I am not a fan of the current labels for communities. Hive-nnnn doesn't communicate what the community is all about, and it's one of the reasons I have not participated in communities heretofore.
Are you aware of any way to translate hive-nnnn to 'cats'? I think that's what you meant in the final lines of your post above, at least that's what I hoped you meant.
I think that would really help communities to be useful.
Thanks!
Thank you @valued-customer.
I am not a fan of these labels either. This was put in place to avoid name-squatting and I think it's a good thing.
Communities are pretty new and I think it will take a few days to see how people use it.
We should quickly see updates, both at the back-end and front-end level. Be patient
I don't know if there are any API available. If not, you have to browse and parse custom_json transactions.
I'm working to provide that kind of info in SteemSQL
Oh damn. Thanks for the update #cats is just what my @busybody needs.
I've played with this a bit and start to wonder..
Is there a mapping of the name to the community?
And won't that be better to map the category to the mapping that have a separate tags table?
It's coming...
Not sure to understand what you mean 🤔
Good for 1st question.
For 2nd question, let me see if an example will help make sense.
So far, the community ends up in category with a hive.... name (I'm just guessing from the pattern). So, with a category name like "hive-146513" which maps to the SteemSQL community, I can join the comments table on category that starts with "hive%" to the mapping table to get the community name to get a more meaning information rather than join the Tags table which result in the comments records being displayed multiple.
With the join the tags table, so happen it's displaying multiple records. So, to avoid that, while I joined to tags to search the tag, I don't display the tag and do a DISTINCT on the rest of the select columns.
Hope that helps or not confuse things further. 😎
This will solve your problem: https://steempeak.com/hive-146513/@arcange/steemsql-community-directories-available
Ah, thanks. I was looking through the views and didn't see the communities ones yesterday.
Good to experiment bit
Works great!
Thank you @inertia. I knew you would like it. To be honest, that's one of your comments about hivemind that triggered my attention and was kind of a kickass to start implementing this.