Decentralized Centralized Fractional Indexing

Arguably the biggest problem with cryptocurrency and decentralization in general is the scaling debacle. With this comes a slew of other problems; one being the complete lack of direction and the thousands of dev teams all running in a different place. Flat architecture is flat: like spilled water on a table.
It's very obvious that crypto will have to find the middle ground:
Just decentralized enough to be robust, secure, and trustworthy, while just centralized enough to scale up and allow powerful leaders to rise up, take charge, and lead us into the future. I believe DPOS is one of many such compromises that will end up working in our favor, with many POW purists dismissing it as garbage tech when in reality it supersedes POW in many aspects (especially governance).
Fractional Indexing
What is an index? In the context of this post, an index would be data on a server stored in RAM for fast centralized access via an API. Anyone that was around when Steemit Incorporated was running the show might remember how their node was blazing fast and everyone else's was pretty much garbage (super laggy and inconsistent). Back when we were storing a ton of information in RAM it cost a lot to run a good node, as the person running it would have to pay quite a bit to store all this data in RAM and then have the bandwidth to dish out the information to anyone that connected to it with the API (application protocol interface). During my programming escapades I learned a lot of how ridiculous it all was.
Example:
You want to query the blockchain for a history of wallet transactions. You do this every time you visit https://peakd.com/@edicted/wallet or https://leofinance.io/@edicted/wallet or https://wallet.hive.blog/@edicted/transfers or https://ecency.com/@edicted/wallet or any other Hive frontend that accesses the wallet. You can also do it manually with JavaScript by connecting to any Full Node API. The vast majority of the time, you make this API call and you don't even realize you are doing it because the frontend in question does all the heavy lifting for you. You simply click the wallet tab and the frontend works it's magic in the background.
This particular API call (operation history) is used quite often and also sucks up a lot of bandwidth, resources, and RAM/SSD storage space within an index. Every Full Node on Hive has this API query available to be called, and anyone can call it and get back the desired information free of charge (because who would pay for something so basic?). The entire concept of APIs and full nodes that operate in this way is very WEB2: people expect free service, and it is hard to go against that flow and put up a paywall or else one would lose 99.9% of their users.
Decentralized Centralized Fractional Indexing
The idea I'm getting at is that every single Hive full node should not have every single possible API call. We don't need 100 nodes that all have the same functionality. If we work together we can create "super-nodes" that do one thing very very well but don't really have other functions that other nodes would. It is in this way that we can scale up because we no longer have to expect that every single full node would provide full service. Together a cluster of nodes would coordinate resources and provide exponentially better service using specialization.

Jack of all trades fails.
If every node is expected to perform every function... we can't scale up... that's just a fact. Or if we do it will be clunky and ugly and totally unprofessional or even downright wasteful. By centralizing certain functions to certain nodes, those nodes will become very very good at what they do and allow other nodes to remove that functionality so that they can go on to specialize in something else that the network needs.
This requires some amount of coordination.
Either that or it requires some kind of request forwarding. For example if someone pinged my node for account balances, but there is another node that does that much better than mine, my node could simply call the other node in the background without the original party ever needing to know how it went down. This creates a little bit of lag because of the chain it creates but it could be worth it on many circumstances (it also uses double the bandwidth). Even better my node could just inform via API that the requestor connects to the source directly to avoid the extra hop/s.
But what even is an index?
Say someone has data stored in their database but their is no index and said data is just floating around in solid state drives (or even worse... disk drives... yuck!). If a call is made that requires that data, without an index in RAM it might take 10 or even 100 times longer to process that request. Sometimes taking that much extra time is not a big deal, but if multiple users are making multiple requests at the same time (or even DDoS attack) it's easy to see how a uncalibrated node could get overburdened quite quickly.
O(1) operations
Say the data you are trying to access is in a linked list. Now say you want to find out if a piece of data is in that list. How many operations does the computer need to perform in order to retrieve the data?
If we know that the data we are looking for is definitely somewhere in the list, on average it's going to take N/2 tries before we find the data (this rounds up to O(n), as there is no O(n/2)). On average, the data we are looking for will be in the middle of the list. Thus if the list is a million Hive accounts long we have to search half a million times on average before we find the account we are looking for. If this sounds bad, that's because it is. If the data isn't even in the list we must search all million "blocks" of data only to come up empty handed.
However, imagine if you indexed the data.
Rather than having to search every single record, imagine beginning the search by sorting all usernames by the first letter. For example, @edicted would be in the 'e' index. Now instead of looking through every single thing in the list, we only have to search through every single thing in the list that starts with 'e'.
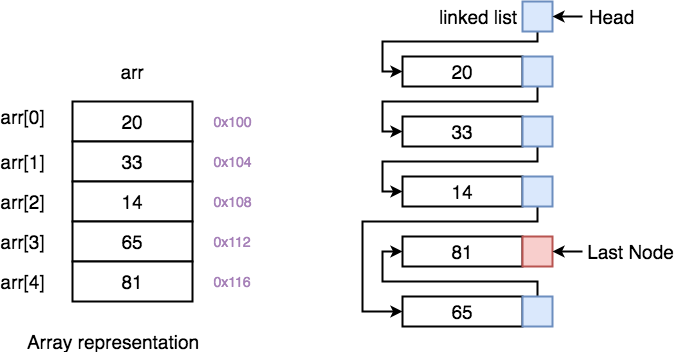
This is the magic of an array.
Unlike a linked list, an array stores blocks of data in addressed memory that are the exact same size (no matter what) in sequential order. This is a very important difference that most who read this will not understand without further clarification (and even then probably not... let's be real). Programming is hard. Optimization and speed are even harder.
So in an array[] we can go to username[4] instantly in O(1) time (near instantly) and know for a fact this is a list of every username that starts with the letter 'e'. That's because the index starts at 0 (letter 'a') and ends at index 25 (letter 'z'). Because every single index is the exact same size, the compiler knows it doesn't have to check the information one by one to get where it needs to go. It 'simply' takes the known size of the data block and multiplies that by the index (in this case 4) to get where it needs to go instantly. This is foundational concept of indexing. We can allocate more resources to a special list that the node uses all the time and make it blazing fast.
Example
The username I want to get to starts with the letter 'a'. The program goes to username[0]. It knows the length of the first letter is only 1 byte long. It multiplies that byte by 0 and adds it to the initial address that the index is stored. Say the address that the index is stored in is something like... I don't know... F2B1 521C 4224 8672. Sure, that means nothing to you, but to the computer this is exactly where it needs to go to access the beginning of the index. username[0] goes to this address, but username[4] jumps to F2B1 521C 4224 8676 knowing full well that's exactly where usernames starting with 'e' are without having to check every entry before it like a linked list would.
What are the tradeoffs?
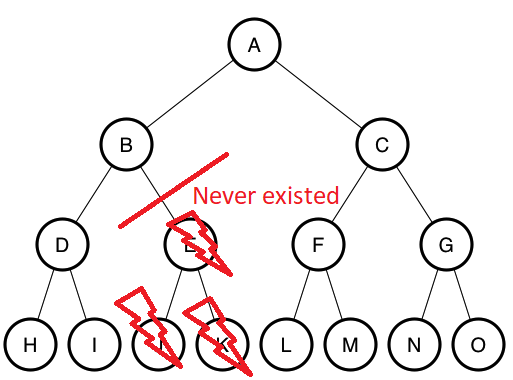
If we look at the picture above, we can see that it is really really easy to add or remove objects from a linked list. All that needs to be done is changing the pointers around to point at the correct block/node. In many situations the data that needs to be deleted doesn't even need to be expressly deleted.
In the C programming language (very low level and fast and difficult) one must allocate and deallocate memory by hand or risk a memory leak that eats away RAM and fills it up with garbage. In more robust/modern (slow) programming languages like JavaScript or Python there is an automatic garbage collector that will destroy the data for you if nothing points to it. This makes bugs and memory leaks far less common but also it won't be as blazing fast as it would be if we used a more low level and hardcore language like C (or even assembly language which is totally nuts and not even object-oriented).
When manipulating an array it is very difficult to add or remove data because an array is a single solid chunk in memory (as described above). It can't float around like a linked list could. If you want to add or remove data from an index/array all of the data needs to be shifted left or right to make room for the new thing or to fill the vacuum that gets created from a deletion.
Thus an index is very bad at adding or removing data, but really really good at accessing the data quickly, while a linked list is essentially the opposite. Many programming languages like JavaScript or Python won't even give you the option to use one or the other (unless you are using a special mod to do so). Rather, modern programming languages will just do things the easy way and expect the programmer to optimize using a more suitable language if necessary (it usually isn't). It is often assumed that SQL databases will handle all this crazy heavy lifting in the background without the frontend scripting languages having to worry about it.
Blah blah blah, who cares!?!
Jibber jabber jibber jabber. Well, anyone who wants Hive or any other crypto to moon should probably care because if we can't scale up then no moon for you, friend. In the world of crypto where everyone is expected to run a redundant node that does everything... optimization is shockingly important. Imagine if Facebook suddenly had to run 1000 redundant servers that all did the same thing. They'd go out of business immediately. Centralized corporations only exist by penny pinching and operating on insanely razor thin profit margins. This is especially true when looking at WEB2 and data monetization + free service + ads. At best one user is only worth like $10 a year on average, if that. Thus, the goal is to have as many users as humanly possible.
Crypto and WEB3 are not like that at all, and we need to learn how to pivot into the correct direction. Rather in WEB3 users are far more valuable, and in the attention economy, they are also getting paid by the networks themselves and performing work that has value to the network. It's a far more balanced ecosystem once we work out the kinks and stop trying to copy the old systems that no longer apply. I imagine things like Fractional Indexing will be a big part of that shift.
Indexes are expensive.
In the example above, the index sorts users by first letter of their username. That's actually... not super helpful. Imagine how unbalanced that index would be. There might be 100k usernames that start with a 'd' but only 1k usernames that start with a 'z'. Searching through a list of 100k names isn't that big of an improvement vs 1M. It would be nice if we could just get there instantly, but that would also be ridiculous, and I'll explain why as best I can.

To retrieve a username instantly, the index would have to be absolutely MASSIVE. Instead of sorting by first letter, the index would have to sort by first letter, then second letter, then third letter, and so and so forth for the maximum number of letters (which is 16 on Hive accounts).
Each letter adds exponential complexity.
The first letter only requires 26 slots in the array. Adding a second letter adds 26 x 26 slots (676), which is still obviously totally doable. However, when we had 26 we knew for a fact that every one of them would get used. Adding the second letter, we can't be so sure. Surely there are no names that start with 'kz' or 'vn' or 'qc' or some other random combination. These derelict containers with nothing in them will just sit there in RAM doing nothing but costing money and filling up space as a placeholder to get that fast access we were looking for.

Add a third letter and we have to multiply by 26 again (17,576). Now we see this getting truly absurd. Not only do we have exponentially more data in the index part of the search function, but most of them will be empty and each box of data is now 3 bytes instead of 1 or 2. By the time we finally reach our goal of getting instant access O(1) search time by having an index for all 16 letters... that's 26^16 boxes of data... or 43,608,742,899,428,874,059,776. As you might imagine... it would take some kind of alien super computer to accomplish such a thing, and 99.9999999999%+ of the data would just be empty space placeholders. Super not worth, thus compromises must be made.
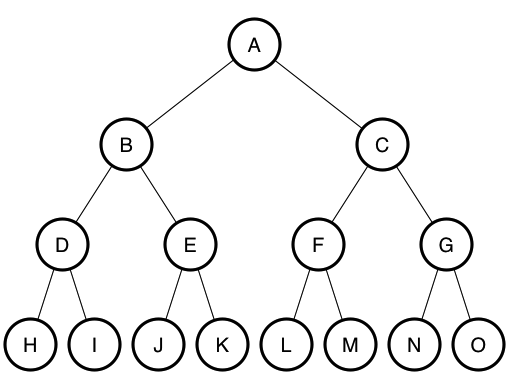
Finding better ways to search millions of data points.
The exponential complexity of such things (which is exactly what makes crypto currency and elliptic encryption so secure) can be greatly reduced using some fancy footwork. For example, the data can be put into a search tree where each level of the tree represents the same letter position of the username. The top level (unlike the one shown above) would have 26 nodes, one for each letter, then each one of those nodes would have 26 nodes, and so on and so forth for all 16 levels and a max length name of 16 characters.
A structure like this avoids the wasted space of an array and has zero wasted space. Every node that exists contains at least one valid username. Imagine there was no such username that started with "ABE". During the creation of the tree, that branch would never exist in the first place, and will only exist if someone creates that username in the future. Thus, 99.9999999999%+ of the branches on this tree would never exist, and the only ones that did exist would be real usernames that actually got paid for with RCs or the 3 Hive buy-in.
What's the tradeoff?
The index that stored every possible combination (43,608,742,899,428,874,059,776) of letters could theoretically access any user instantly just by doing some simple multiplication and accessing the correct location in memory. This tree has to be accessed once for each letter in the username. @edicted has 7 letters so it would have to make 7 hops before the correct data was found. Considering the tree is infinitely smaller than the index (and actually possible to implement within this context) that's a damn good tradeoff.
Also a big advantage to the tree is that nodes don't have to be of equal size and the data can float around in memory. The tree is a linked list solution that gets a lot of benefits of both worlds if implemented well. Data can be searched quickly and added and removed quickly. No matter how many Hive accounts there are, finding the data will only take at most 16 jumps to find even if billions of accounts were created.
SQL databases and indexing.
Most programmers never even have to deal with any of this stuff. These days it's all automated in the background and you really only have to get down and dirty if you're managing an unwieldy database. Unfortunately for the owners of crypto nodes, they are basically inefficient unwieldy databases by design. The more optimization we do, the better. However, even then we can tell a database to index the data we want indexed without having to tell it which solution to pick. The default is often good enough unless the node becomes bogged down by certain requests and requires even more tinkering.
Conclusion
Perhaps this is a sign that I will start programming again. I certainly hope so... HAF tech for Hive will be out soon and I would love to launch MAGITEK here.
We absolutely need to be thinking about how WEB3 is different than WEB2 and how we should be pivoting to avoid the bottlenecks of the legacy systems. If a network like Hive is running hundreds of redundant nodes, shouldn't we work towards making them less redundant and more harmonious and synergistic?
Scaling up will always be crypto's number one issue because that's exactly what exponentially robust and redundant systems have the hardest time doing. Our focus needs to be on teamwork and monetizing things that WEB2 could never dream of monetizing (like micro-charging for data/bandwidth and paying users who create value with that data like proper employees of the network).
The first networks who evolve to do these crazy things first (without crippling UX) will open a floodgate of value to the entire cryptosphere. It's not a competition, but it certainly doesn't hurt to be at the front of the line.
Posted Using LeoFinance Beta
Programming seems to me very complicated because I don't have enough brain to understand such areas you've discussed. Only understand what Facebook use hahah!
Ha ha, really it looks an advantage in this Web3 network, but me too it’s like a foreign language.
Absolutely, web 3 will be the game changer valuing its users.
Reading all the above seems you are a good programmer and you should not delay it @edicted 🙂
@edicted has always surpass my expectations because is the house for talented, dedicated and wise people. among all decentralised social media that exist today, hive is the only complex Blockchain that simplify it's complexity. Web 3.0 is already changing the world. Thanks for this writeup. Ivet always learnt lot from you
Indexes are useful but only for the things you tend to use often. Otherwise, the extra storage space isn't really worth it. Then deciding between a hash or a tree is also kind of important depending on how you are looking for data. I think you just plan on using the database optimizer right? It generally does a good job of deciding when indexes are worth using.
Posted Using LeoFinance Beta
Yep just do it the easy way until the easy way doesn't work.
Thanks for this update
Pls keep updating on cryto for more😍🥰
This is great way of explaining stuff I've come to understand: especially about the distribution of roles in Hive between Witnesses, full API nodes and now the forthcoming simpler application specific HAF nodes we'll be able to build.
I like this direction, with the advent of this blockchain technology, new developments keeps coming. If you look at decentralized platforms like https://atomicwallet.io/, you would appreciate the innovative features.
Wow, what a wonderful explanation, I really learnt a lot from this post
Ha! I understood username[4] and username[0] and was so excited, then I got a bit lost :-) I just decided to start learning to program and I see I have a lot more to learn.
Well. Journey of a thousand miles and all of that. Just started today actually. Made it through a bit of python. Been thinking about it for a while and had all kinds of excuses (age, time, etc.). Also have had paralysis of analysis and worried about planning the perfect learning curriculum....blah blah blah. Just decided to start with python and go from there. Hope to be running my own node sometime this year :-) Maybe by years end I'll come back and re-read this :-)
Posted Using LeoFinance Beta
what about a (hive)browser that stores data like cache data. I mean that would be IMO the most efficient to limit the requests, special for dapps.
People will watch the same wallets in social media more often. So wallet data can be in cache and update only new transactions.
Can be manipulated, but who cares is local and only to make the network more efficient and cheaper to run.
Also, it could be used to display ads paid in hive/HBD :) And for 1000 other cool things. Because decentralized funded browser ( chromium fork?),
So you want to start programming again? Please build it! :)
And yes I know 1 thing is the requests and another thing is the scaling. So both are very different things.
But both together have a synergy :)
Se ve que hay que aplicar teoría de árbol, y arreglos como los que usaba en turbo pascal en mi época de estudiante y SQL, muy interesante todo eso..
Isn't the reason we have 100 nodes geographically distributed is so that if some nodes go down (hardware problem, electricity outages, the guy running the node dies etc), the other nodes keep the network going?
You need some duplication and redundancy in the system for resilience. If you just have a few super-nodes, you have a point of failure if they get taken out.
Hey @edicted. This seems a lot like what we are doing at @spknetwork for our offchain indexing approach. We are working on a system to divide up the entire dataset between multiple nodes (slightly different than splitting up the index). Meaning a node doesn't have to store the entire dataset of all offchain content. In the event the node does not have the desired content (for example newly created comments under a post), the node can send out a special query to other nodes asking for new information. We utilize IPFS pubsub channels for communication with bloom filters to improve exchange efficiency. For the actual data itself we use Ceramic to provide us data mutability which is built directly on top of IPFS. Exchange speed will naturally be slower than storing directly, but that can be improved by prioritizing low latency peers.